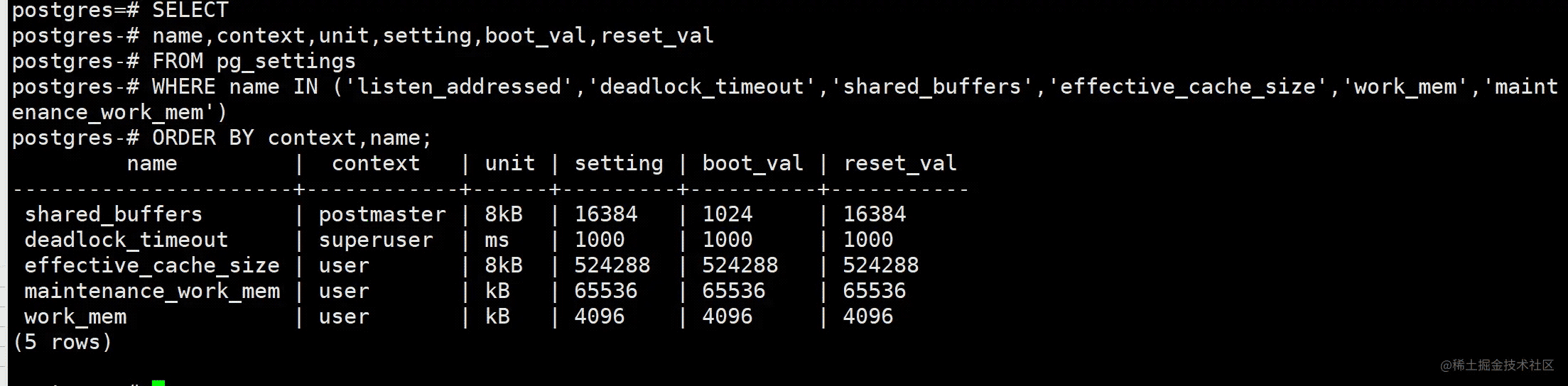
文章摘要
这篇文章介绍了使用Python的`urllib`模块进行编码和解码的相关知识。文章重点讲述了如何将字符串从`str`格式转换为Unicode,并使用`urllib.quote`和`urllib.unquote`函数实现编码和解码。文章还强调了不同编码格式(如`gbk`和`utf8`)对结果页的影响,并提供了一个示例代码,说明了如何根据系统环境自动选择编码格式(`sys.stdin.encoding`),以确保代码的移植性。文章还提到不同编码格式会导致相同字符串在不同平台上的表现不同,例如`%E4%B8%BD%E6%B1%9F`代表“丽江”在`utf8`编码下,而在`gbk`编码下则表示为`丽江`。文章还提到了一些相关的话题,供读者进一步学习。
复制代码 代码如下:
>>> import urllib
>>> data=’丽江’
>>> print data
丽江
>>> data
‘\xe4\xb8\xbd\xe6\xb1\x9f’
>>> urllib.quote(data)
‘%E4%B8%BD%E6%B1%9F’
那我们想转回去呢?
复制代码 代码如下:
>>> urllib.unquote(‘%E4%B8%BD%E6%B1%9F’)
‘\xe4\xb8\xbd\xe6\xb1\x9f’
>>> print urllib.unquote(‘%E4%B8%BD%E6%B1%9F’)
丽江
不同的编码格式对urllib的结果页是有影响的,百度的是gbk,其他的一般网站比如google就是utf8的。所以可以用下列语句实现。
复制代码 代码如下:
>>> import sys,urllib
>>> s=’丽江’
>>> urllib.quote(s.decode(sys.stdin.encoding).encode(‘gbk’))
‘%C0%F6%BD%AD’
>>> urllib.quote(s.decode(sys.stdin.encoding).encode(‘utf8’))
‘%E4%B8%BD%E6%B1%9F’
>>>
这里的 sys.stdin.encoding 是读取当前环境的编码,这样写的话可移植性高,winnt和xunix都可以用。当然你如果看不惯,也可以替换为自己的环境编码如utf8等。
您可能感兴趣的文章:Python中解析JSON并同时进行自定义编码处理实例Python如何获取系统iops示例代码python3编码问题汇总用Python实现命令行闹钟脚本实例Python爬虫爬取美剧网站的实现代码Python选课系统开发程序简单谈谈Python中函数的可变参数Python实现自动添加脚本头信息的示例代码利用Python获取操作系统信息实例好用的Python编辑器WingIDE的使用经验总结Linux下为不同版本python安装第三方库Python 编码处理-str与Unicode的区别
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章